BizReachプロダクト開発部、SREグループの久保木です。5月頃に中途で入ってきて、今はinfrastructure中心に開発に従事しています。
最近はlog生成周りをいじっていった結果、生成元であるapplicationもいじれるようになってきた気がします。あとはfrontendいじれば制覇かな!(<どこに行く気なの?)
ところで、元々僕は何かを作る時に延々とmemoがてら作業進捗を書いていく癖があります。
それで作業が一区切りしたところで、
「あれ、これ記事のネタになるんじゃない?」
と思ったので書いてみることにしました。ボリュームがあるので連載にてお送りします。 どうぞよろしくお願いします。
- 前編: 概要
- 中編: 技術調査・設計
- 後編: 七転八倒ログ
何があったのか
まず、前提。
BizReachのapplicationはlogをS3に飛ばして、そこからなんやかんやあって(後述)、Redshiftへ飛ばしています。
しかし昔は特に問題は無かったのですが、最近Redshiftを(というかRedshiftに貯めているdataを)使いたいという部署が増えてきました。
当然重たいqueryも走ります。同時に走ったりします。重くなります。Alertが飛びます。残念じゃった……。いや残念で終わっては困るのです。
ということで何とかしようという話、は後々出てくるのですが、ここは試しに「BigQuery」を使ってみたい、という話がどこからともなく降って湧いてきました。
実際BigQueryなら大概のQueryは一定の速度で解決してくれるとうろ覚えで聞いた気がします。うろ覚えが正しいのなら先に上げたような問題にはぴったりでしょう。
だが待って欲しい。
- 元々のdataはAWSのS3にある
- BigQueryはGCP(Google)にある
……んー。さて、どうしようか?
いやきっと方法はいろいろあるんだろうけど(この頃まだ方法も知らない)、どういう風に組むのがいいのだろう。というかなにげにMulti Cloudだ。Cloud横断の構成ということを意識した方がいいのかもしれない。そもそもGCPのServiceはどんなものがあるのかも知らないから設計時点で結構調べることあるなー。いやそれ以前に僕、BizReachに入った直後で既存の仕組みもまだ把握できてないんですが? わぁ……。
まあやってみよう!
ということで、S3に蓄積しているlogをBigQueryに取り込ませる仕組みを組んでみることになりました。
結果
さてここから先は一つ一つどういう手順で七転八倒、もとい調査し設計し開発し「あれ?」と思って引き返してまた作り直したかという開発日誌な文章になります。
ですが「それはともかく結局どうなったのか、まずは結果を見せて欲しい」という方向けにここで早々にどんなものを作ったか紹介します。
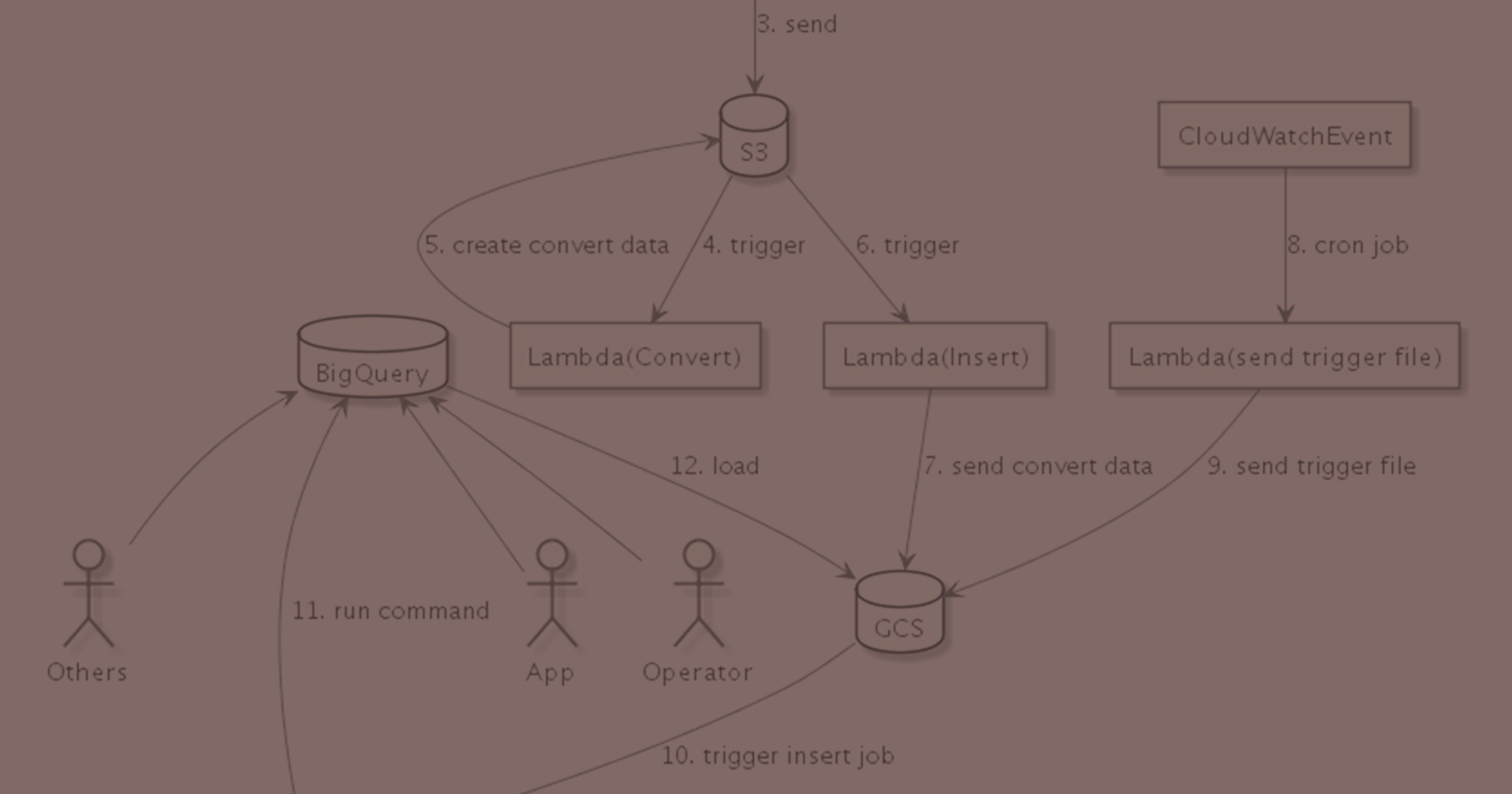
しかし全体像を説明するにはいろいろ前提があります。その前提なしでいきなり最終形を解説するのは難しいです。具体的には以下の図を説明することになります。
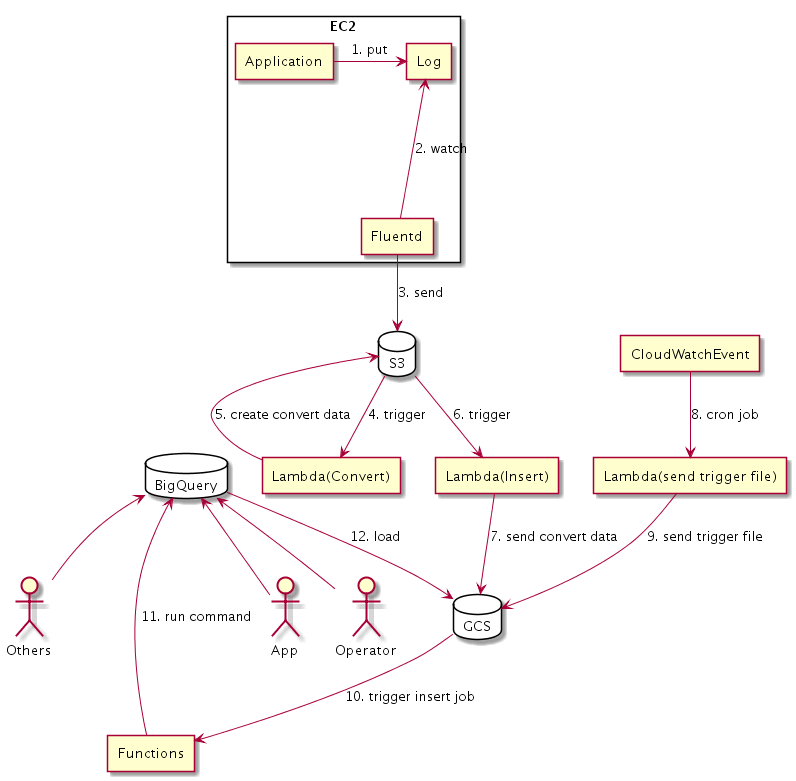
つらいですよね?
なので要点として「S3に蓄積したlogをBigQueryに投入する仕組み」について先に以下で解説します。
仕組みは大きく2つに分かれます。「S3に蓄積されたlogをGCSに転送する仕組み」と「GCSに蓄積されたlogをBigQueryに投入する仕組み」です。
1. S3に蓄積されたlogをGCSに転送する仕組み

- FluentdからlogをS3に保存します(BizReachのlog基盤で元々実装されていた機能です)
- S3にlog fileが保存されたことをtriggerにlambdaを起動します
- lambdaがGCSにfileを配置します
BigQueryに直接recordを登録するstreaming insertという機能もあるのですが、今回はDBが壊れた時の再登録等の仕掛けを実装するにあたって、一度GCSに蓄積してクッションを置く、という手順を取っています(詳しくは後述)。
**ちなみに、**GCS側にS3とGCSでfile同期する機能があることが判明しますが、今回のSystemの開発当時はそれを知らなかったので逐次file転送をしていました。
2. GCSに蓄積されたlogをBigQueryに投入する仕組み
さて一度GCSに蓄積したのだからあとはこれを定期的にBigQueryに登録するだけです。
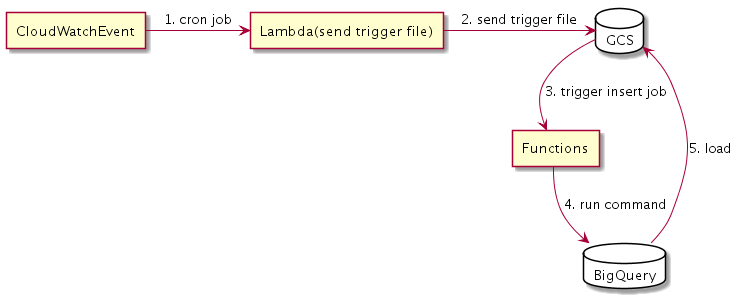
- CloudWatchEventからcronでlambda関数を実行します
- lambda関数がGCSの特定prefixにfileを保存します
- GCSにfile保存されたことをtriggerとしてgoogle cloud functionsが起動します
- functionsがBigQueryにfile情報に沿った期間のdataを取り込むようcommandを発行します
- BigQueryがdata取り込みを行います
取り込み開始の実行triggerがCloudWatchEvent経由という迂遠なやり方になっていますね。GCPのみでも似たような仕組みは作れますが、このためだけにGCPのServiceをいくつか新たに設定できるようにして、しかも今後利用する余地があるかどうかまだ疑問、という状態だとSystemとして迂遠ですよね。
それに実装としてまず実行できるところに持っていきたい(構成できたはいいけれど実際BigQueryを使うのも初めてなのでどの程度利用できるかわからない。のでまずは触れるようにしたい)、という動機もありました。結果としてこういった構成になりました。
それでは……
次回以降はどのような経緯を経て上記Systemが出来るに至ったか、というお話になります。
BigQueryの仕様にはまったり、いろんな機能を見つけては当てが外れたり、あちらこちらに向かっては戻り向かっては戻りしてたどり着いた行程を楽しんで読んでいただけたら幸いです。








