BizReachプロダクト開発部、SREグループの久保木です。
今日は連載中編の「AWS S3に蓄積したlogをGoogleのBigQueryに投入する仕組み作り」の技術調査・設計をお送りしたいと思います。どうぞよろしくお願いします。
- 前編: 概要
- 中編: 技術調査・設計
- 後編: 七転八倒ログ
事前調査1. BizReachの既存のLog移送の仕組み
さてまずここはどうなっているんだと調べてみたわけですよ(突然何を主張したいんだお前は)。残っていたテキストや伝聞、実際にserverに入ってあれこれ叩いたりしながら洗っていくわけです。
で、大まかにこんな感じ、ということはわかりました。
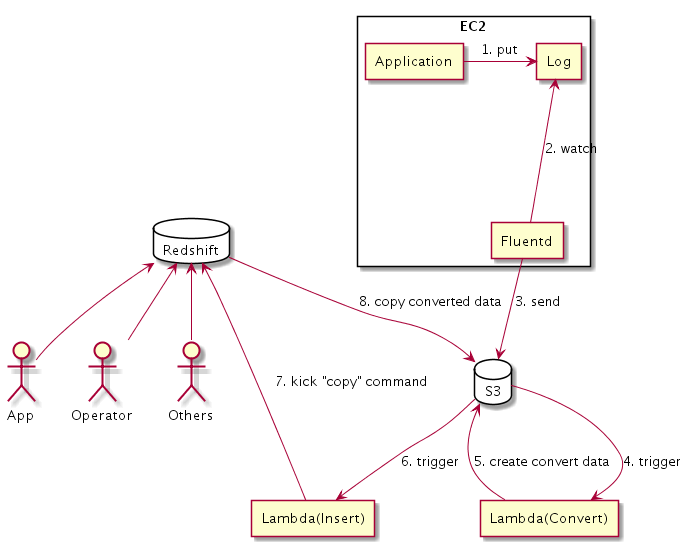
- ApplicationがLog Fileに書き込み
- FluentdがLog Fileを見ながら、適宜S3に書き込み
- S3にFileが書き込まれると、Lambdaがtriggerされて、DB書き込み前のいろいろな前処理をする
- S3に前処理を終えたfileを書き込むと、別のLambdaがtriggerされて、Redshiftに書き込む
実際には書き込み頻度が多くてRedshiftへの書き込みがうまくいかなくなった時など、他いろいろ配慮してもう少し別の仕掛けがあちこちにあるのですが、今回の話をするに当たっては必要ないので無視します。(実際に調べるときはそこも潜って、浮上して、「あれ、僕は何を知りたかったんだっけ?」ということもしばしばあったよ。くぬぅ。)
とはいえこれだけわかればなんとかなりそうな目処が立ってきます。必要なのはconvertしたあとのlog fileであり、ここをなんやかんやしてBigQueryに書き込めればいいわけです。たぶん。そうだよね?
そのなんやかんやをこれから考えるのです。
事前調査2. BigQueryとは
これから扱うものについてくらいは知っておきたいというのが人の常。ということでなんやかんやを考える前にBigQueryについても少し調べてみましょう。
C#エンジニアのためのBigQuery入門(1)誰でも簡単に超高速なクエリができるBigQueryとは?
BigQueryはGoogle Cloud Platformが提供するビッグデータ解析サービスである。いわゆる「ビッグデータ解析サービス/ソフトウェア」はいくつもあるが、BigQueryは数TB(テラバイト)あるいはPB(ペタバイト)に及ぶデータセットに対し、SQLに似たクエリを実行し、数秒あるいは数十秒程度で結果を返すというサービスである。
application logでそこまででかくなることはないと思うけどまあそこは今回はどうでもいい。
BigQueryを特徴づけている仕組みとしては、カラム指向なデータ配置とツリーアーキテクチャが挙げられている。
tree architectureって何?
一方、クエリを実行する際、ツリーアーキテクチャと呼んでいる機構で、クエリを分割統治している(図3)。カラム指向で配置したデータを並列にスキャンし、そこで読み取った結果を高速に集約してクエリの結果を出している。
ってよく見たら元々の論文があったよ。その図によると、こういうこと。
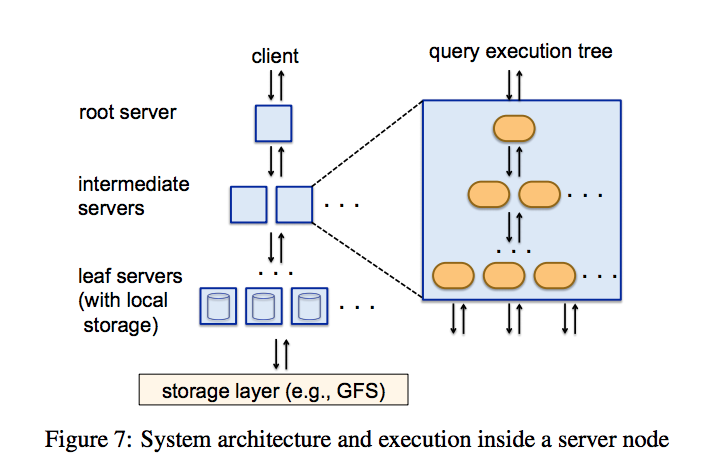
これこれ。dataはColumnarのDBだからそれに沿って分けつつ、queryの分割統治とは? queryもうまく分割しているらしいことはなんとなく説明からもわかってくるけどもう少し掘り下げたい。
クエリはRoot/Mixer/Slotの順で伝播します。その時Slotのみで解決できないQuery要素に関しては排除されて伝播されます。Slotは実際にStorageレイヤと通信し最初の処理をするLeaf Serverのスレッドのことのようです。そして、処理結果がSlot/Mixer/Rootの順で伝播し、それぞれ統治処理が行われます。
ここの説明は同じ意味だよね。
そのあといくつかあるqueryごとのどういう動作するかの話が面白い。
次のようにGroup Byがある場合も分割統治型で処理されます。 (省略) まず Order句とLIMIT句を排除してSlotに渡しクエリし、その結果をMixerに渡し、Mixerでは元のクエリをかけて終了です。ただしDistinctなKeyが多い場合メモリに乗り切らずabortします。
へー。なるなる。段々先の図と動きが頭の中で一致してきた。
さてJoinですが、単純な場合としてJoinする片方がSlotにバラまけれるサイズであれば分割統治型の繰り返しで対応できます。(BigQueryでは 8mbが閾値のようです)。こちらは
- サブクエリSELECT fugue FROM bのみをSlotに配布
- Mixerに結果が返される
- 返された結果をインライン展開して、全体のクエリを配布
- Mixerに結果が集められ、Aggregationして終了 一つ面白いのは、例えば5000 Leafあれば 5000 x 8MB = 40GBのネットワークコストをかけている、というところです。
おおうパワーイズパワー(語彙力消失)。
It takes more than just a lot of hardware to make your queries run fast. BigQuery requests are powered by the Dremel query engine (paper on Dremel published in 2010), which orchestrates your query by breaking it up into pieces and re-assembling the results.
ああこのqueryの切り方仕組みのことをDremel query engineと言うのか。
queryもうまく分割して最終的に一定速度で処理できる数にだけ分離して一気に解決するからどのくらいでかいdataでも一定時間で解決する、という話らしい。いやそれを実現するためにはいろいろな苦労があるのはわかるけれど。実現するのはすごいなぁ……。
こういう仕組みなら複数人が一斉にDBに取りかかろうと速度的な問題が起きることはなさそう(その代わり一人でやろうと早くなるわけじゃないけど、そこは今は課題としてない)。
ということで、ありがたく使わせてもらいましょう。
(注意: 僕の理解が間違ってたら丁寧に教えてくれるととても嬉しいです。とりあえず僕は今のところこんな風に理解してます)
設計
調べ終わった。満足した。
違うそうじゃない。僕は何をやりたかったんだっけ。
そうだ。S3に蓄積したlogをBigQueryに投入したいんだった。
既存の構成やBigQueryがどういうものかといった知識が頭に入ったので、これをもとに設計を始めることにしよう。
だがどんな投入方法があるか調べないと
そうだよBigQueryにどうやってdataを投入するかわからないと何も決まらないじゃないかぁ。ということで調べる。
で、三つくらい方法を見つけた。
1) Streaming Insert
https://cloud.google.com/bigquery/streaming-data-into-bigquery
ジョブを使用して BigQuery にデータを読み込む代わりに tabledata().insertAll() メソッドを使用することで、一度に 1 レコードずつ、BigQuery にデータをストリーミングできます。このアプローチを使用すると、読み込みジョブの実行遅延を発生させることなく、データのクエリを実行できます。
sample code見る限りpython等でも書けるみたいなので実際やるならS3->lambda->(streaming insert)->BigQueryという経路になるかな。
いやでも、今回いれたいlogに関して言えば別段realtime性は要求してないんだよなぁ。いやあっても悪くはないけれど。そうすると新しくlogと投入先tableが増えた時とかはどうしようかな……tableを増やしてからlogを増やすに決まっているか。
ちなみに有料。正常に挿入された200MBあたり$0.01。個々の行は、最小サイズを1KBとして計算されます。とのこと。
2) FluentdのPlugin
fluentdのpluginであるのかい。でも10万行で0.01$か。ほうほう。
とはいえ実はbizのfluentdの設定が結構大変なことになっているので残り時間で調べていじるのは厳しいかも、との助言をもらう。今回はこれはなしか……。
3) GCSからのImport
GCSを経由すればどうあれcommandなりで取り込めるのか。commandで行けるならfunctionsとかでもいける気がする。
実質これとStreaming Insertの一騎打ちだなぁ。
では構成を考えてみよう
今考えられる方法としては以下の3つ。
- fluentd => GCS or BigQuery
- S3 => Lambda =(Streaming Insert)=> BigQuery
- S3 => Lambda => GCS => BigQuery
fluentdから直接やるのはどうだろう?
今回はまずbigqueryにいれる動線を作ることと、いれたdataを期待通り扱えるか確かめたい、という目的だとのことだったので既存の仕組みになるべく影響を与えない形に倒すことにする。
とすると、convert後のlogをBigQueryにいれる方が手軽。fluentdから直接入れ込むにはそのあたりも改めて何か作る必要が出てくるので今回はなし。この時点でfluentd起点はなし。
残るはS3からの経路だけど、Streaming Insertを使うかGCSを使うかの2つ。
Streaming Insertはどうだろう?
残る方法は2つなんだけど、ちょっと考えて見よう。
Streaming Insertでいれた場合、失敗時の扱いとかどうしようかな……。
Streamin Insertでいれる場合はS3 => Lambda => BigQueryという形でS3にfileが置かれた後triggerされたlambdaを用いることになるんだろうけど、失敗した場合、retryの機構をここで組む必要がある、と。
あとはそのときそのときの失敗だけじゃなくて、DBが壊れるなりlog移送がおかしくなったりするなりして、ある日付分まとめて入れ直したい、となった場合の仕組みを作る場合はどうしようか。こういうまとめて入れる処理が入ってくるとBatch的な処理になってくるのでわざわざStreaming Insertに一気に流すのも筋が違うように思える。というよりそうなった時はStreaming Insertの流量制限も考慮しないと行けないのか。
んー。Recoveryの仕組みに寄せて考えるなら、いささかチープだけどBatch処理でいいかな?
S3 => Lambda => GCS => BigQueryの方式で言えば一度はGCSに蓄積されるわけだから、あとは1日に1度取り込むという方式で作っておけば、毎日の取り込みもRecovery時の入れ直しも同じ仕掛けで実施できる。
その上で今回扱うlogに関してはRealtimeでdata投入する必要はない、ともわかっている。
ならこれかな。これで書いてみよう。
ちなみに: 実はもう一つ、S3からGCSへdataを送る方法があることに、これを作っている途中で気づくことになる……(後述)
落ち穂拾い
では方針が決まったところでもう少し詰めてみる。
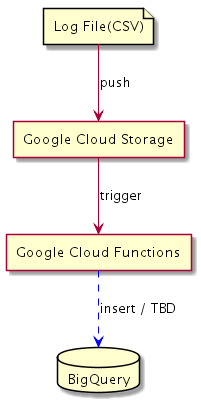
GCSからBigQueryにいれるにはどうしたらいいのか
こういう方法でできる、と。いやcommandでやりたいわけではない。
Google Cloud ベストプラクティス:Google BigQuery 編 - 02 : データ処理 / クエリ / データ抽出
このslideではdata loadingと言っている。そのkeywordで調べれば出てくるかな?
結局ここにたどり着く。本家のdocumentをさっさと見なさいと神様に言われた気分になるね!
まだ概要。具体的ないれる方法を知りたいのです。
ためしにCSVでの読み込みを見てみる。
Google Cloud Storage から CSV データを読み込む
お、各言語でのsource codeが出ている。
そういえばgoogle cloud functionというものがある。awsでいうlambdaのようなもので、これはnodeで実装できる。ここで実装すれば行けそうな気がしてきた。(わざわざこのためにinstance上げたくないし……)
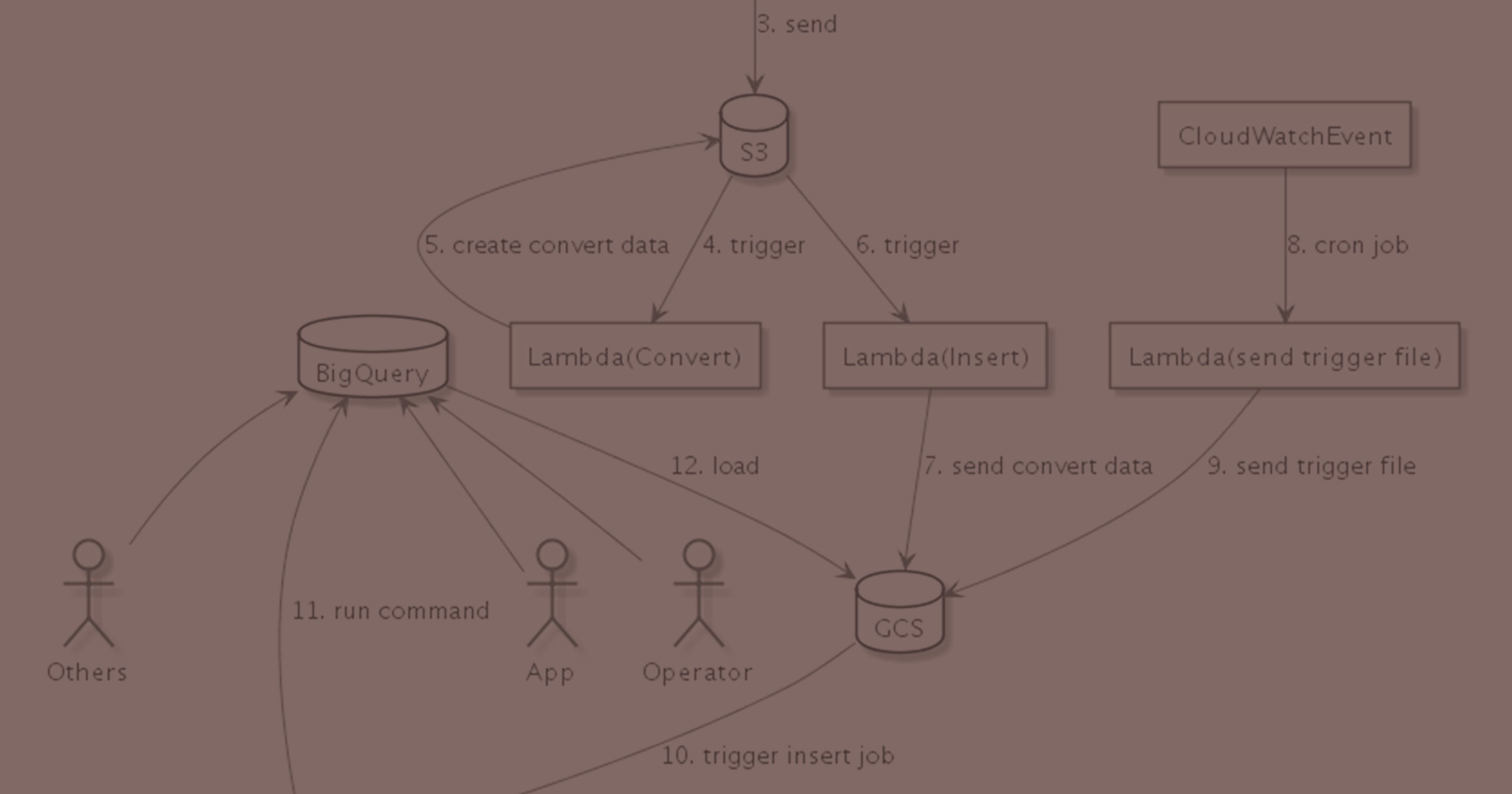
ここまでを図に起こすと、こんな感じになる。
functionsの中の実装はたぶん「Google Cloud Storage から CSV データを読み込む」を参考にすれば出来る気がするので、ここまでは一区切りとする。駄目だったらそのとき調べよう。
ということで図に起こしてみる
まず、これまでがこうだった。
これが、
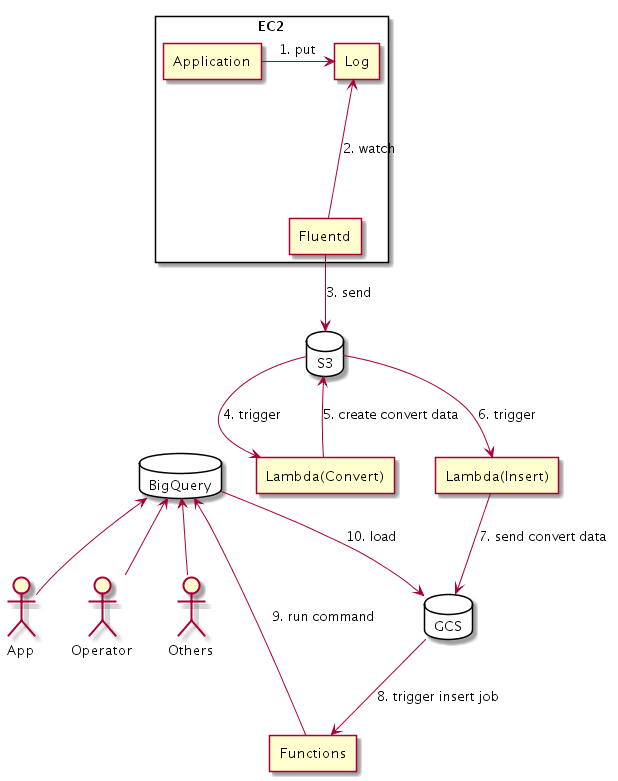
こうなる。図がでけぇ……。
でも図としてはS3に取り込まれた後から既存の部分はほぼいじらずにつなげられたような気がする。必要とあらば既存の部分をいじるのは構わないけれど、今回そこの手入れが目的じゃないし。これでやってみよう。(余談:後々、別のtaskでいじることになりました)
そして
当然すんなりいくわけないのです。次回は七転八起ログをお送りします。よろしくお願いします。








