
こんにちは、BizReach で DBRE チームをやらせてもらっている あわっちです。
先日 孤高にきらめく執行役員 園田より、
DBRE(Database Reliability Engineering)チーム始めました
が掲載されましたが 結局具体的には何をしているの? という声にお応えする為、私たちがどんな思想で活動を決めているのか、また具体的に何をどんな技術で何をやっているのか、をお伝えさせていただきます。
BizReach の DBRE / DBA Role
組織体制
BizReach には大小10以上のサービスが存在し、それらのサービスほぼ全てで MySQL、もしくは PostgreSQL のような Relational Database を使用しています。
その中の代表的なサービスであるビズリーチや HRMOS といった事業体力があるサービスには専属のDBAが複数人存在しています。
(私自身、入社は 2018年03月だったのですが、この時はビズリーチの DBA として入社しています。)
逆にその他の事業では DBA という明確な Role が存在せず、事業のエンジニアが (良く言えば)フルスタックに Database 関連の作業をする、という体制になっています。
そうなると必然的に専属の DBA がいる部署といない部署で Database そのものの運用方法や、管理の質に差が出てきてしまいます。
また事業のエンジニアの中に存在する数少ない Database に強い人材が異動や退職でいなくなった場合に、残されたエンジニアの心の平穏が保てなくなってしまい、健康的にアプリケーション運用をしていくことが難しくなる、なんてこともあるかもしれません。
これらのよくある解決策としては Database Administration を中央集権の形にし、管理運用をそこで行う、という方法です。
しかし (BizReach の場合) Database Administrator としての作業はアプリケーションそのもののソースコードや仕様と密結合し過ぎてしまっているため現実的に難しい状況でした。
また、限られたリソースでは事業の実現したいスピードに合わせられないケースが発生し、中央にいる DBA と Application Engineer の間に無意味な壁が出来てしまうかもしれません。
そこで私たちは DBRE として Engineering という側面から各事業の Database Operation に関する手助けを行う、といった方向に舵を切ることを決断しました。
DBRE とは
Database Reliability Engineering はあくまでも概念であり役割ではありません。 Database Reliability Engineering - O’Reilly Media にも書かれていますが
これからの Database Professional は Administrator ではなく Engineer であるべきである、という思想が根底にあります。
各事業のエンジニアの自律性を尊重し、その方々の活動を最大化させるために、Database の管理運用に対する Monitoring Policy を決めたり、Database Operation Platform を開発し提供したり、
トラブルが発生した際などはトラブルシューティングを行い、現状復旧 -> 根本原因 -> Postmotem などのプロセスを経て正常な状態を維持したりすることなどが挙げられます。
私たちの場合はまだこのチームが出来たばかりであり、 理想だけを求めて DBRE を実践していくにはまだまだ時間もリソースも経験も知識も足りないものばかりです。
だからこそ、こうあるべき、ということに固執しすぎず、これから柔軟に BizReach 流の DBRE を進化させます。
DBRE チーム Vision
- Make it Visible
- No Ops, More Code
私たちの全ての活動はこの2つの上に成り立っています。
チームを作る際に、「この部署はお金を生み出す部署ではない、事業に対して Value を提供できないとただの税金になってしまう」ということを何度も認識合わせを行いました。
その上で事業に対してどういった Value を提供したいか、を抽象化した言葉を Vision として設定しました。
これらの言葉は、チームが新しいことをする。となった場合のやる、やらないの判断、自分たちのアウトプットの指標としてこの2つに落とせるか、をしっかりと見つめ直させてくれるもので、大変重要なものです。
DBRE チームのアクティビティ
Backup Platform の開発
こちら にもある通り、現在私たちは Backup Platform の開発を行っています。
今回はこれがどんなものか、を具体的に紹介させていただきます。(今後 Masking Platform や Monitoring Platform などこの TechBlog で連載していければと思います。)
背景
BizReach はそのほとんど全てを AWS や GCP などの Managed サービスで運用しています。特に比率が高いのは RDS や Aurora などの AWS で提供されている MySQL系 Relational Database サービスです。
「え? ここまで来て今更 Backup?」と思った方もいらっしゃるかと思いますが、その通りで、DBA という Role が存在する組織や会社であれば当たり前に行われていることでしょう。
実際 DBA が存在するビズリーチサービスでは Backup に対する手段とその運用が確立されています。
しかしながら、規模の小さい事業や、新しく出来た事業にはその知見やリソースがなく、RDS による 自動 SnapShot しか取っていない事業も存在してしまっているのも現実としてあります。
現段階では最低限事業継続のために必要なこと(Point In Time Recovery や Monitoring など)は AWS の仕組みにお任せすることに振り切っています。
とはいえ、おかげさまで BizReach という会社も順調に育ってきている為、AWS の自動 SnapShot だけでは会社を存続するための要件を満たせなくなりました。
具体的には個人情報や決算に関わる情報はレベル分けされ、それぞれX年保持する。という会社独自のポリシーです。
皆様からお預かりしているデータなのでそれを安全に堅牢に保持し、不測の事態に備えるために重要なことです。
AWS では保存できる Snapshot の数そのものに 制限 があったり、これからずっと(弊社が決めた長期的な保持期間) SnapShot が Restore できるとは限りません。
その為、私たちは PITR などのサービス継続に必要な backup に関しては RDS の機能で、それ以外では Statement Base でファイルに保存するという方法を選択しました。
開発におけるスローガン
- 実現できる事は枯れたコトかもしれない
- でもそれを今っぽい技術を使って実現できたら僕たちも面白い
この言葉の通りですが、実際に Backup Platform として開発して出来上がってたものはものすごくレガシーなことです。
業務要件や性能要件を無視すれば極端な話
|
|
とcronに仕込めばいいかもしれません。
とはいえ Backup 取得することによって、Database Server の負荷が上がって本番サービスに影響を与えてしまっては本末転倒ですよね。
幸いにも私たちの所属する部署には組織横断的にインフラ基盤を整備するグループが存在するので、その方々の力を借りて Database Operation を Cloud Native ならではの方法で実現させることを考えながら技術選定を行い、開発をしています。
その1番の理由は私たち自身が Database だけでなく、インフラのトレンドを追い続けたい欲求があったからだと思います。
アーキテクチャ
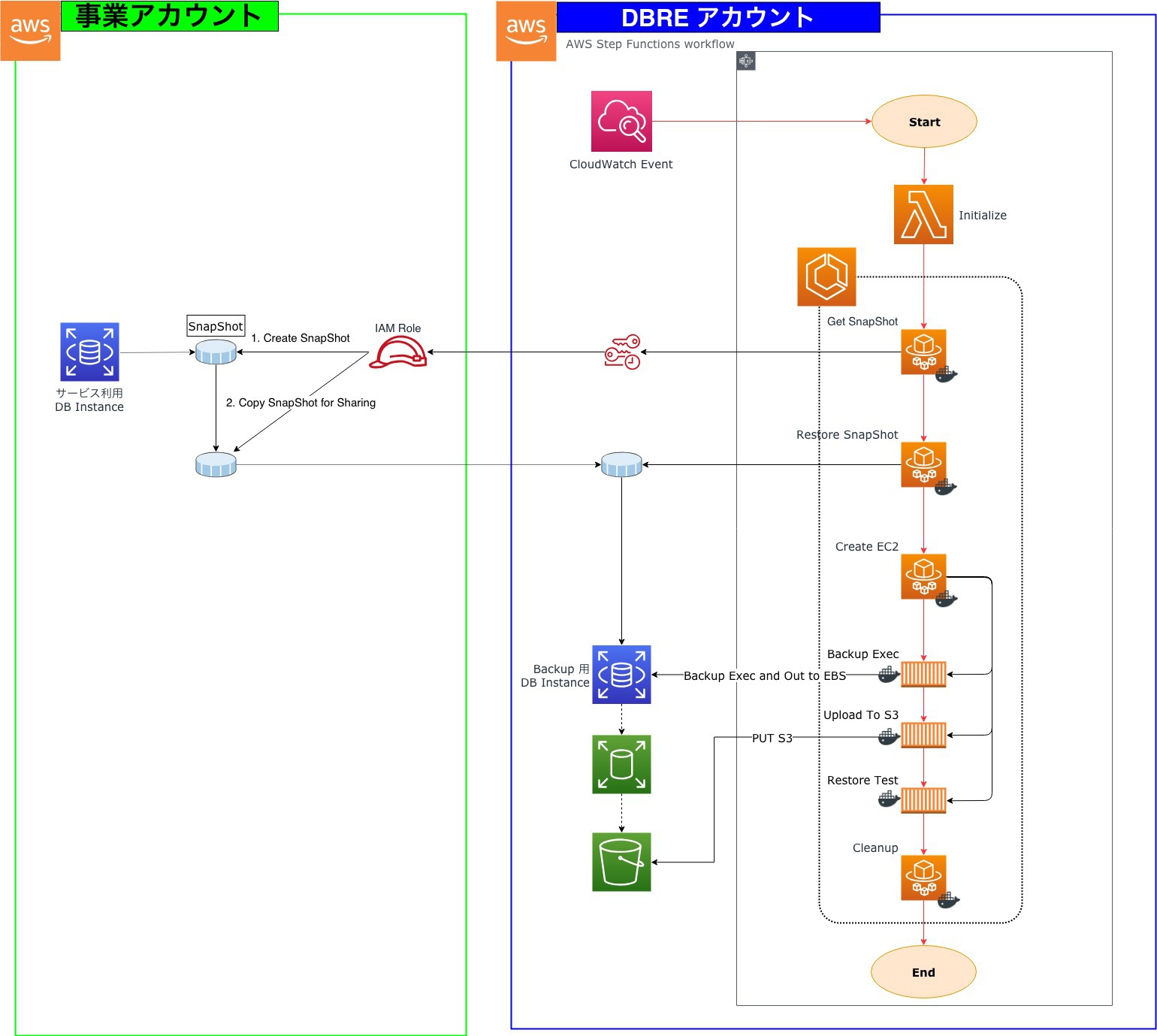
前提として 事業が使っている AWS アカウントと DBRE チームで管理しているアカウントは別物です。それを踏まえてこの図をごく簡単に説明させていただきます。
- Initialize
- Get SnapShot
- 事業内の RDS で SnapShot を作成、コピー、DBRE チームアカウントに共有
- Restore SnapShot
- DBRE チーム内のアカウントに共有されたスナップショットを展開
- Create EC2
- dump用の ECSコンテナインスタンスを作成
- Backup Exec and Out to EBS
- テーブル単位でパラレルにバックアップしEBSに保存
- Upload To S3
- EBS から S3 に PUT
- Restore Test
- Cleanup
この仕組みは mysqldump の部分を別の、例えば pg_dump に変えれば PostgreSQL に対応できたり、データマスキングの仕組みに組み替えればマスキングプラットフォームができたりと使い回しができることです。
本当は完全に Serverless で行いたかったのですが、これらの処理は時間がかかったり、ディスクI/O を消費してしまうので今回は Docker で EBS をマウントして解決をしています。
この仕組みを入れるために Fargete では実現できなかったため、一部で ECS On EC2 の環境を利用しています。
そしてこれらの処理に必要なリソースは使用中に立ち上げ、処理が完了したら綺麗に掃除しているので本当に必要な時間帯のみ起動するように設計しました。
また、Backup された File 自体は Restore テストまで完了した時点で余程のことがない限り人が触れることがあってはならない為、独立した S3 環境に配置するなど、セキュリティ的にも厳重に管理保管しています。
(この詳しい仕組みに関しては今後この Blog などを通して発信したいと思います。)
せっかくここまでコード化されているので、今後ナレッジを貯めることによって、例えば 全体のディスクサイズや 1テーブルあたりのディスクサイズを確認して、この Database は処理に時間がかかりそうだからインスタンスサイズを上げる、それでもダメならディスクサイズに応じて例えばi3ストレージを使ってみる、などアーキテクチャそのものも自動的に、柔軟に選択できるようにしたいと考えています。
最後に
長くなりましたが、いかがでしたでしょうか?何となくでも私たちの考えているDBREについてイメージが持てましたでしょうか?
今回は Backup Platform に特化してお話させていただきましたが、今後も継続的に私たちのアクティビティを紹介していければと思います。
レッツジョイン
DBREチームを発足はしたのですが、とはいえやりたいことに対して仲間はまだまだ足りません、実はまだDBREチームの専任は2名です!
DBREに興味のある方、是非ご応募ください。いまDBAやってるよって方からソフトウエアエンジニアやSREだけどDBREに興味あるよって方もご応募お待ちしております。
採用情報のページはこちら DBRE









