
こんにちは、BizReach で DBRE チームをやらせてもらっている あわっちです。
今回は DBRE としてデータマイグレーションをサポートした際のサービスとの関わり方と手法について、令和最初の Tech Blog として紹介します。
DBRE というよりも、 DBA という要素が強いかもしれませんが、サービスサポートも私たちの重要な役割の1つです。 前回のDBRE(Database Reliability Engineering) の活動 〜 Backup Platform 編 〜とは少し違って泥臭いオペレーションのお話になりますが、お付き合いいただければと思います。
ビズリーチサービス Restart Project
Slow Query 撲滅に向けて
ビズリーチサービスはサービス開始から10年が経過しましたが、データの肥大化による Slow Query の増加が問題になったり、 1つのカラムで複数の意味を持ってしまっているなど、データそのものが煩雑な状態になっており、サービスの継続に影響を与える状況が発生していました。
例えるならば 重りを乗せてマラソンさせている 様なイメージでしょうか。
この状況に危機感を持ち、アラートを上げたところ、5ヶ月以上に渡って、 新規開発を止め Slow Query の解消を含めたテーブルリファクタリング、
エラーログの解消を含めたアプリケーションモジュールのリファクタリングなど、非機能要件に全力を注ぐ、という決断が下されました。
今回はその中でキーポイントになった テーブルリファクタリング時の初期データ投入方法 についてお話しさせていただきます。
テーブルリファクタリング時の初期データ投入方法
方法例
テーブルリファクタリングに関しては様々な資料で紹介されています。サービス停止の時間を最小化するための、一般的な方法を雑に記載すると下記の様な形になると思います。
- 新規の DDL を本番環境に適用
- 本番データからデータセットを抜き出して新スキーマに import
- トリガーなどをはじめとしたDBの機能で import、 もしくは 更新処理をしているアプリケーションの箇所に変更を加え、2つのテーブルに同時に書き込みを行う (ダブルライト)
- Read 処理をしているアプリケーションモジュールを1つづつ修正して全ての Read モジュールが切り替わったら 変更前のテーブルを削除する
上記はほんの一例だと思いますし、また、その時の Database の状況によってアプローチは大きく変わると思っています。
(そもそも私自身はサービスを止めてでも完全に定点を取得し、その上でデータマイグレーションを行いたいタイプの人間でした。)
この中で、具体的に初期データの投入に関して言及しているものはあまり多くないと思ったので、初期データ投入にフォーカスしてお話ししたいと思います。
今回多かった例として下の図の様に2つ以上のテーブルの情報を取得し、1つのテーブルを作るという要件があります。 A Table の中から B Table のある条件にマッチするものだけを New Table に入れてアプリケーションの実情に沿ったスキーマ設計に直すことが狙いです。
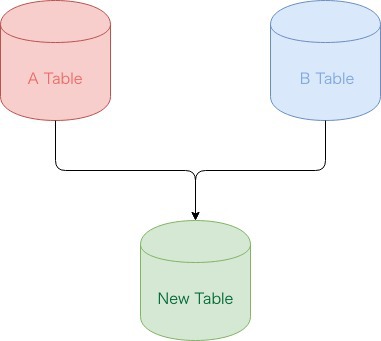
テーブルリファクタリング方法に関して
前提となりますがビズリーチサービスでは主に RDS for MySQL を使用しています。その上で私たちが取ったアプローチを紹介させていただきます。
- Master に新規スキーマを反映する
- Master から新規で Replica を作る
- Replica を Stop Slave し
定点を取得 - Replica に対して
新規スキーマと構成がほぼ同じTmp Table を作成 - 初期データセットを tsv で出力
- Tmp Table に load data
- Tmp Table から mysqldump で DML を取得
- Replica を Start Slave
- Master に 1 行ずつ Insert
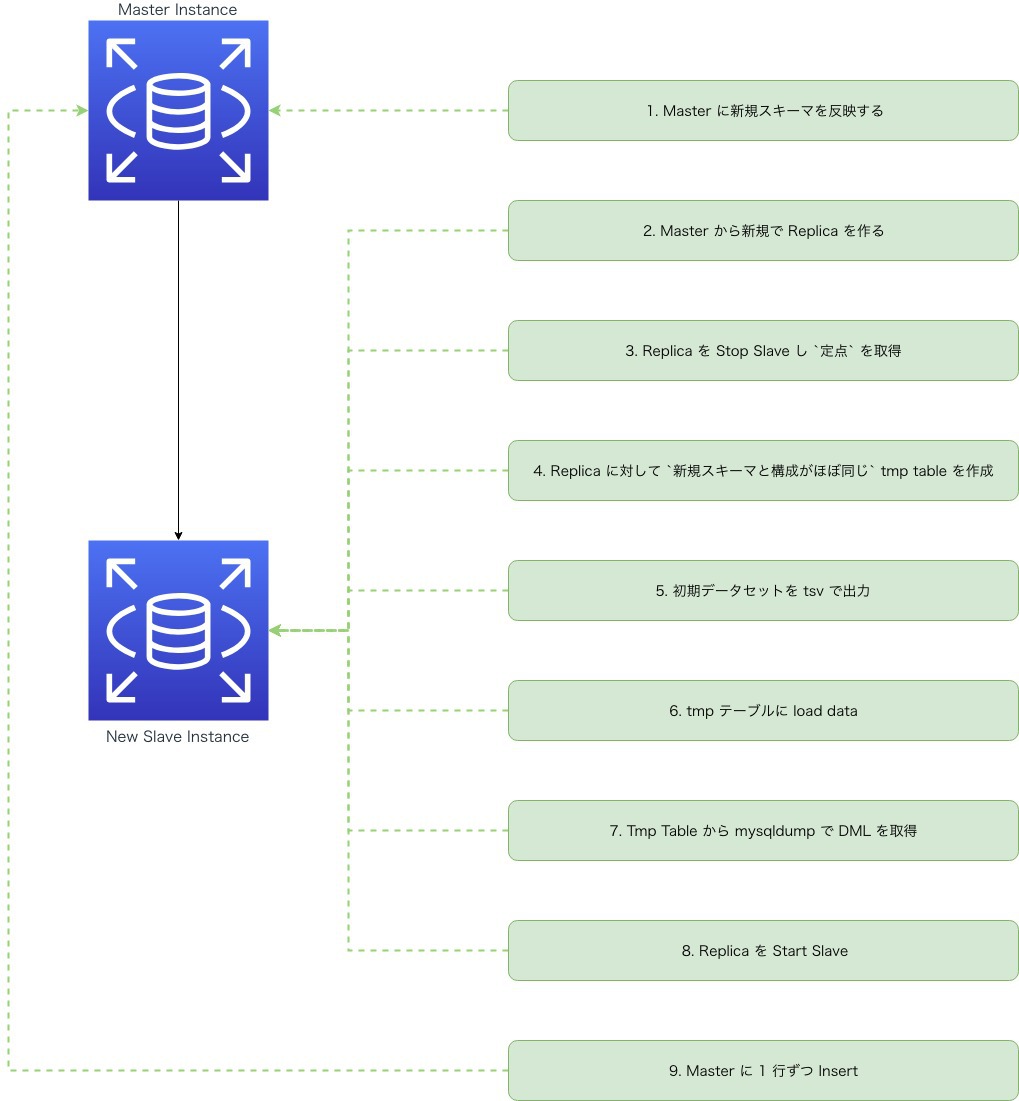
ざっくりとした流れですが、上記の様な方法をとりました。 仕様によって様々な方法が取れるので、それほど使い回しが効くものでもなかった為、割り切って Shell Script でライトに組みました。
(ライトと言いつつ 2,000 行超えてしまいましたが。。)
続いて、「なぜ Tmp Table を作ったのか」「なぜ dump を取得して一行づつ Insert する方法を取ったのか」など合わせて、このスクリプトの仕様を簡単に紹介させていただきます。
1. Master に新規スキーマを反映する
事前にリファクタリング後のテーブルを Master に反映しておくことで後々の作業がしやすくなるので、あらかじめスキーマリリースをできるタイミングで行っておきます。
2. Master から新規で Replica を作る
1 で行われた新規のスキーマ定義が反映された状態で Operation 用の Replica を作りました。 ここは Migration しか行われない為、多少負荷が上がったり、 Replication 遅延が発生してもほとんど気にせずに作業できるメリットがあります。
後述しますが、この Replica には Tmp Table を作成するなど、本番とは別で WRITE 処理をさせる為、Master - Slave 間でスキーマの違いが発生することを前提としています。 これらを実現させるために、途中で read_only を切り替える必要があるので、他の Replica とは別の Parameter Group を用意しました。
3. Replica を Stop Slave し 定点 を取得
新しく作った Replica はアプリケーションからのリクエストを一切受け付けていないので、 Stop Slave した時点で Start Slave をするまでデータが更新されることはありません。 逆に Start Slave がされればその間にされた更新情報は反映されます。コマンド的には該当の RDS 上で下記を実行するだけです。
|
|
もちろんこのタイミングで一緒に Slave Status をチェックすることも忘れません(笑)
Slave_IO_Running, Slave_SQL_Running のどちらも止まっていることを確認します。
|
|
4. Replica に対して 新規スキーマと構成がほぼ同じ tmp table を作成
Replica に対して 書き込み 処理を行うことになるので、 Parameter Group のうちの read_only を Off にします。
|
|
反映までにタイムラグがあるので
|
|
を実行して確実に OFF になったことを確認します。
この上で該当の Replica 上に Create Table します。
ここで 新規スキーマと構成がほぼ同じ と言っていたのは単にデータロードの時間を短縮するために、不要な INDEX や Foreign Key は全て削除しているものを作成した、という意味です。
ただし、Unique 制約は外すと事故を起こす可能性高いので Unique Key は外しませんでした。
5. 初期データセットを tsv で出力
サービス側に提供してもらったクエリを流してファイルにリダイレクトします。
この際の注意点としては、
- データマイグレーションは大量データを扱うため、
--quickオプションをつけないとクライアントサーバ側が処理できなくなってしまう - オリジナルのデータに NULL があった場合に tsv ファイルで出力したものをそのまま入れると NULL という文字列になってしまう
という点です。
特に NULL に関しては取り扱いが面倒でした。
例えば文字列型であれば、使われないであろう文字列 NNNNUUUULLLLLLLL という文字列に置換したり、日付であれば 0000-01-01 00:00:00 、数値であれば -1 (該当のテーブルで マイナスを扱う必要が無かったため)
など、カラムの型やその用途に合わせて置換を行いました。(確実な正解があるわけではなく、これらの値が入っている可能性も捨てきれないので SELECT を行ってから決める必要があります)
|
|
基本的に私たちはクエリのシンタックスを気にする程度で、UNLOAD する為のクエリ自体はサービスの仕様に詳しいエンジニアに作ってもらいました。
クエリそのものを私たちが作らない、というのはサービス直属の DBA ではない為、サービスの仕様を理解できておらず、スキーマ情報だけでは判断できないマジカルな仕様を知らなかったということもあります。
もちろんやりたいことを聞いて、その上で一緒にクエリを作ったり、作ってもらったクエリを確認して Operation 用の Replica のみ に INDEX をつける、など Database に限られたことは行います。
6. tmp テーブルに load data
出力したファイルを LOAD DATA INFILE 構文を使ってデータを import していきます。
とはいえ、あまりに大量データを一気に流すと処理が途中で落ちてしまうため、今回は 10万行ずつ split して実行しました。
また --show-warning オプションを付けて、全て正常終了することを確認します。
全データが入った後、 Before で取得した件数と Tmp Table に入ったデータの件数が合っていること、また置換した文字列が正しく NULL で入力されているかをチェックする。ということも合わせて行いました。
この NULL チェックのやり方を簡単に説明すると
- 該当のテーブルから NULLABLE なカラムリストを取得
|
|
- NULLABLE なカラムを入れながら チェッククエリを作って流す
|
|
- 置換した文字列が入ってないかを同じ様に確認する
|
|
これらを組み合わせてチェックしていきました。
7. Tmp Table から mysqldump で DML を取得
今回 mysqldump を選んだのは net_buffer_length の範囲内で、バルクインサートをよしなに分割してくれるためです。
Master に対して一気にデータを import すると FK の Lock や Replica Lag (レプリケーション遅延) などが発生し、結果としてサービスに負の影響を与えてしまうことが想定されます。
この後記載しますが、どうやって Master に対して負荷を最小限にしつつ、確実に流し込むか、そして 一番楽に 出来るか、を考えた結果 mysqldump という選択に至りました。
8. Replica を Start Slave
Start Slave の前に read_only を OFF に戻す必要があるため、aws コマンドから実行します。 この時 read_only を ON にしたタイミングから OFF に戻すまでの時間が短いと、正常に反映されなかったため、Sleep とリトライを組み合わせて対応しました。
|
|
|
|
9. Master に 1 行ずつ Insert
出力されたステートメントを 1行ずつ流し Sleep を入れることで、サービスから流れてくる更新ステートメントを出来る限り邪魔せずに Replication に渡す様にしました。 また、万が一何か問題が発生した場合に処理を停止した場合でも Rollback が走った際の影響を少なくできます。
そうすることにより、サービスに対する影響を最小限にして、データを確実に入れられる様にしました。
これが少し遠回りをしてでも最終的に mysqldump を使って初期データを入れることを選択した1番のメリットです。
データ投入後 〜 アプリケーションモジュール(ダブルライト) 〜 Read モジュールリリースまで
上記手法でアプリケーションを稼働させつつ、ある定点下での初期データの投入は無事にできました。 とはいえ、やはりサービス稼働状態にある、ということを考慮すると初期データ投入からアプリケーションモジュールリリースまでの間に、データ更新がなされることを前提に動く必要があります。 ビズリーチサービスは、アプリケーションモジュールリリースのおよそ2時間前、というタイミングが多かったです。
そのため、初期データ投入からアプリケーションモジュールリリースまでの間に発生した差分を改めて取り込む必要があります。
専用の Replica を Stop Slave した上で 上記5 で使用したクエリと同じクエリを流す
この時点で入っているべき全データは、初期データ投入で使用したクエリと全く同じであるはずなので、これをまずは流します。
New Table を全件取得
この全件と、上記で取得した全データの差分がその2時間の間に更新されたデータである、ということで、その差分を新テーブルに INSERTします。
ここでの考え方として重要なポイントは 割り切り です。
NEW Table 上のデータはまだアプリケーションから見られていない、という前提で、DELETE - INSERT という選択をしました。 対象のデータが入っていれば DELETEしてから INSERT、入っていなければ INSERT を行うことで帳尻を合わせます。
これを何度も繰り返すことで差分が少しづつ解消され、最終的に0になったら Read モジュールのリリースが出来る、といった判断ができます。 もちろんダブルライト自体にバグがあることによって差分が発生することも考えられるので、出力された差分は一本一本見ていく必要があります。
(特に月末月初のタイミングで走るバッチなどの考慮は欠かせないですね)
こうして無事に初期データ投入が完了しました。
Shell Script で MySQL を叩くときのコツ
Shell Script からクエリを流す場合に下記のように作業をしていた方も多いのではないでしょうか。
|
|
MySQL 5.6以降ではこれをこのまま叩くと
|
|
のように Warning が標準出力されてしまい鬱陶しいですよね。
Shell Script の場合、これを下記のように対応してあげると Warning が出力されずスッキリします。
|
|
mysqldump コマンドでも同様ですね。
私の場合、手が勝手に -p を入れてしまうのと MYSQL_PWD が大文字なので、意識しないでできるようになるまでは苦労しましたが(笑)、 慣れてしまうととても使い勝手がいいです。
使ってない方がいらっしゃいましたら (きっと MySQL 歴が長い人ですね) 試してみてください。
まとめ
またまた長くなってしまいましたが、今回はテーブルリファクタリングの中で特に頭を悩ませる初期データ投入の部分に対する私たちのアプローチについてお話しさせていただきました。
もちろんこのやり方以外にもたくさんの方法がありますよね。
データマイグレーションは特に仕様だったり、テーブルの特性で様々な手法を取ることになるので、このタイミングでは Shell Script で組むという Platform-nize しづらい方法を選択してしまいましたが、今後需要があれば Step Functions などを利用する、ということも検討したいと思います。
余談: ビズリーチサービス Restart Project の現在
まだ完全にリファクタリングも終わっていませんが、現在のビズリーチサービスは徐々に健康的な状態を取り戻しています。
INDEX 戦略も同時に行うことで Slow Query も順調に減っています。
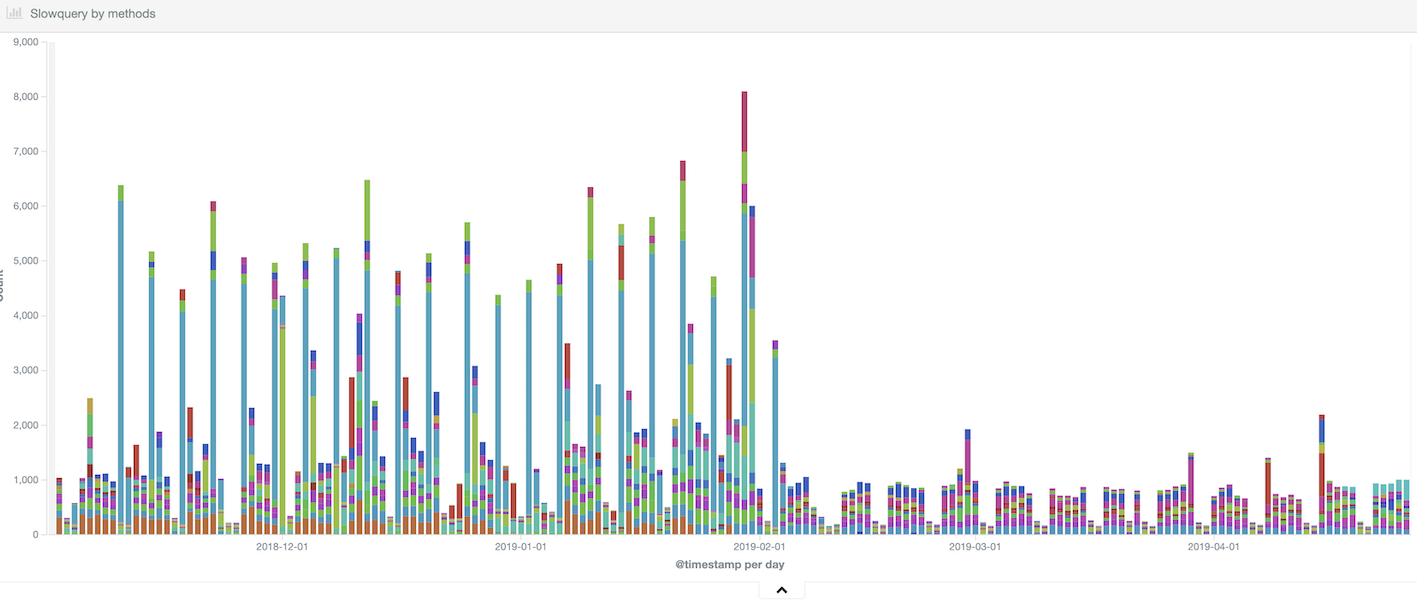
Slow Query 撲滅という名目で何ヶ月も新規機能のリリース止めることは、普通の会社では難しく、それを理解して推進してくれた執行役員、MGRs、そしてサービスのアプリケーションエンジニアの皆に理解してもらえたことに大変感謝しています。
アプリケーションエンジニアにとっては面白くない期間を過ごさせてしまったかもしれないことは申し訳なく思っていますが、この取り組みによって DBA だけでなくアプリケーションエンジニアが Database を意識してコーディングをしていく。 といった文化形成がなされ、アプリケーションエンジニアにとっても DBA にとっても過ごしやすい環境になりました。
レッツジョイン(お約束)
DBREチームを発足はしたのですが、とはいえやりたいことに対して仲間はまだまだ足りません、実はまだDBREチームの専任は2名です!
DBREに興味のある方、是非ご応募ください。いまDBAやってるよって方からソフトウエアエンジニアやSREだけどDBREに興味あるよって方もご応募お待ちしております。
採用情報のページはこちら DBRE









